
Современные алгоритмы искусственного интеллекта поражают воображение: пишут тексты, рисуют картины, сдают экзамены. Можно подумать, что скоро половина офисов опустеют, потому что целые отрасли окажутся не нужны. Может и так! Но как на смену ручному переписыванию книг пришел печатный станок, а работы сильно меньше не стало (но стало больше книг), так и завтра могут возникнуть новые профессии, связанные с включением новых, более эффективных инструментов в работу людей.
Несмотря на то, что большие языковые модели могут успешно решать задачи, решению которых их не обучали специально, они не могут решать любые такие задачи, а кроме того, требуют для работы целый вычислительный кластер. Поэтому для специальных задач, требующих экспертных знаний, не теряют актуальности задачи дообучения больших моделей или обучения более простых специализированных моделей. И чтобы обучать алгоритмы (как, собственно, и студентов) все еще нужны размеченные данные: «задачи» и «ответы». Что там будет, то модель и выучит, поэтому репрезентативность задач и правильность ответов очень важны. Иначе получится «забудьте всё, чему вас учили в университете, на заводе всё иначе».
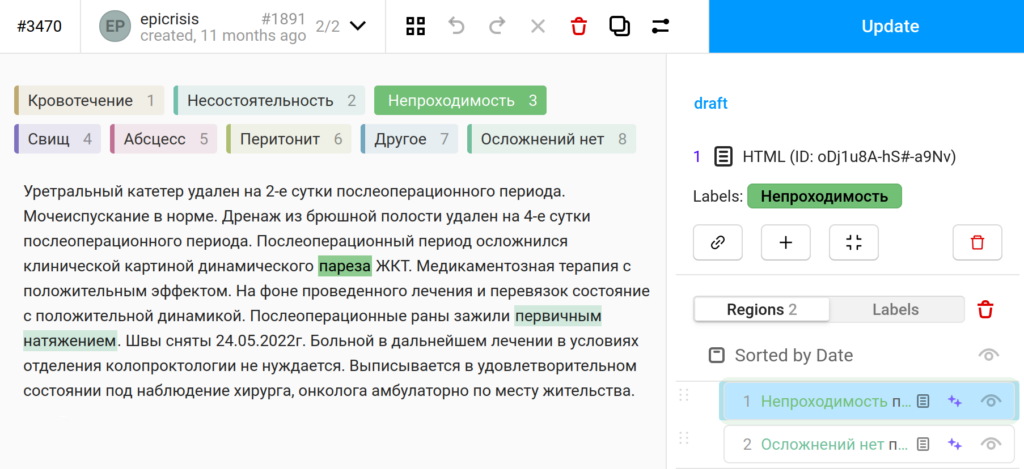
Находить пожарные гидранты на фотографиях улиц умеют более-менее все, а вот со сложными экспертными задачами иногда оказывается, что даже профессионалам трудно прийти к общему мнению. Когда пару лет назад мы начали заниматься цифровой медициной, врачи рассказали нам анекдот, что «где два врача, там три мнения». Что получится в таких условиях, если просто раздавать клинические случаи и без проверок сохранять ответы? Понятно, что ничего хорошего. И хотя, конечно, не любые медицинские задачи такие, но как узнать заранее?
Поэтому в нашей научной группе мы как раз и занимаемся вопросами эффективной организации получения качественных наборов данных: как раздавать задачи? Как оценивать степень согласия экспертов? Как отфильтровывать некачественные ответы? Нельзя ли часть рутины свалить на роботов? Не обленятся ли эксперты?
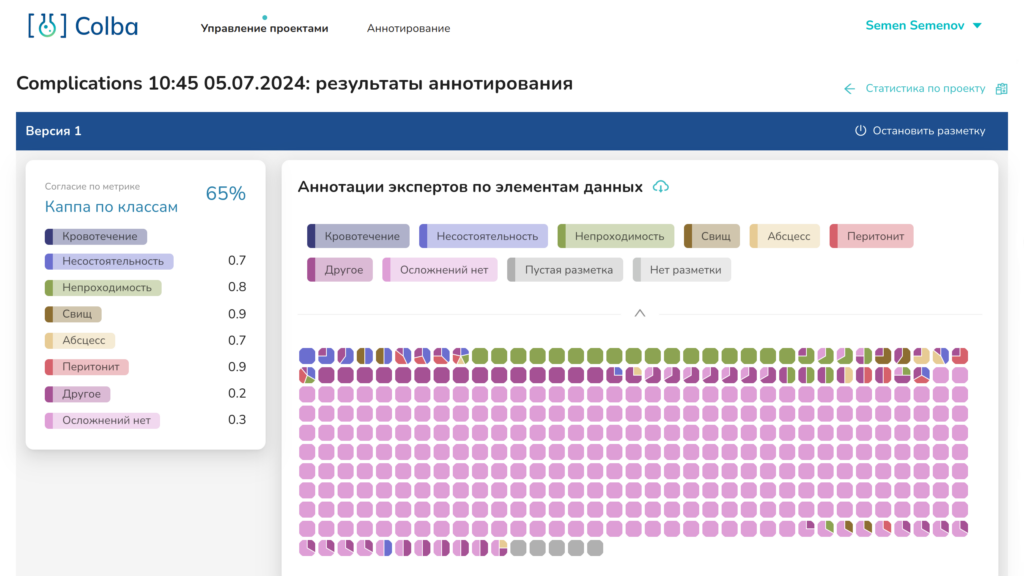
Все свои разработки включаем в нашу технологию ИСП РАН: Колба. Код пишем в основном на Python и Typescript. Публичного демо у нас пока нет, но вот выше скриншотики как раз из неё.
| Направления работы | |
|---|---|
| Модель процесса аннотирования | Как можно организовывать аннотирование? Тестирование экспертов? Парная работа? Как вообще устроены эксперты, от чего зависит вероятность ошибки? Как выстроить их взаимодействие с системой, чтобы её минимизировать? |
| Оптимизация выбора очередной задачи | Как дешевле всего получить максимально качественные аннотации для данных задачи и экспертов? |
| «Мониторинг» качества набора данных | Как по полученным аннотациям возможно заранее понять, получится ли обучить на этом какую-то модель (тут рядом и AutoML)? |
| Фильтрация аннотаций | Где шум, а где сигнал? |